Introduction
You just finished an amazing movie and you are unsure what to watch next? Don’t worry we’ve got you covered!
Every movie you watch has a unique signature, a blend of themes and ideas beyond simple genres. What if the key to finding your next favorite
film is not in the usual categories like "action" or "romance," but in uncovering deeper, hidden topics that truly reflect the movie?
In this analysis, we dive into the art of movie recommendation. Using Latent Dirichlet Allocation (LDA), a tool for discovering hidden topics
in movies’ plots, we go beyond surface-level genres to identify the intricate themes that define each film. These topics form the foundation of
a content-based recommendation system, helping us find movies with similar thematics.
At the end of the datastory you will also have the chance to test our movie recommendation system, to help you choose which movie you will watch this evening.
During this adventure we will try to answer the following questions:
- What topics can be recovered using LDA on the movie synopsis?
- Do these topics reflect the genres or labels from the MPST dataset?
- Are topics enough for movie recommendations?
- What additional features should we consider?
For our task, we use three different datasets:
- CMU Movie Summary Corpus: Our original dataset contains 42’306 movie plot summaries that have been extracted from Wikipedia, as well as metadata data extracted from freebase which includes revenue, title, genre, release date, runtime and language. Download the dataset here
- MPST: A dataset of movie plot synopses with story-related tags (aka labels) contains 14’828 movies from which only 94 did not have a match with our original dataset. From the MPST dataset, we retrieved the synopsis of the movies as well as their tags. Download the dataset here
- IMDb ratings: A dataset containing the weighted average of all the individual user ratings of a movie and the number of votes for it. Download the dataset here
Data Exploration
Before diving into the core part of the project, let's take a closer look at the datasets we're working with. In this section, we will analyze the data sources, highlighting the key information that will be critical for our analysis. This will help us better understand the structure of the datasets and identify the relevant features that we need to focus on in order to draw meaningful conclusions.
The Genres That Steal the Spotlight in the Movie Industry
Let’s roll the reel and uncover which genres are the true stars of the show and maybe stumble upon a few hidden gems along the way!
First, by analyzing the CMU Movie dataset, we see that we have 333 different genres in the database. Let's find the most recurrent ones:
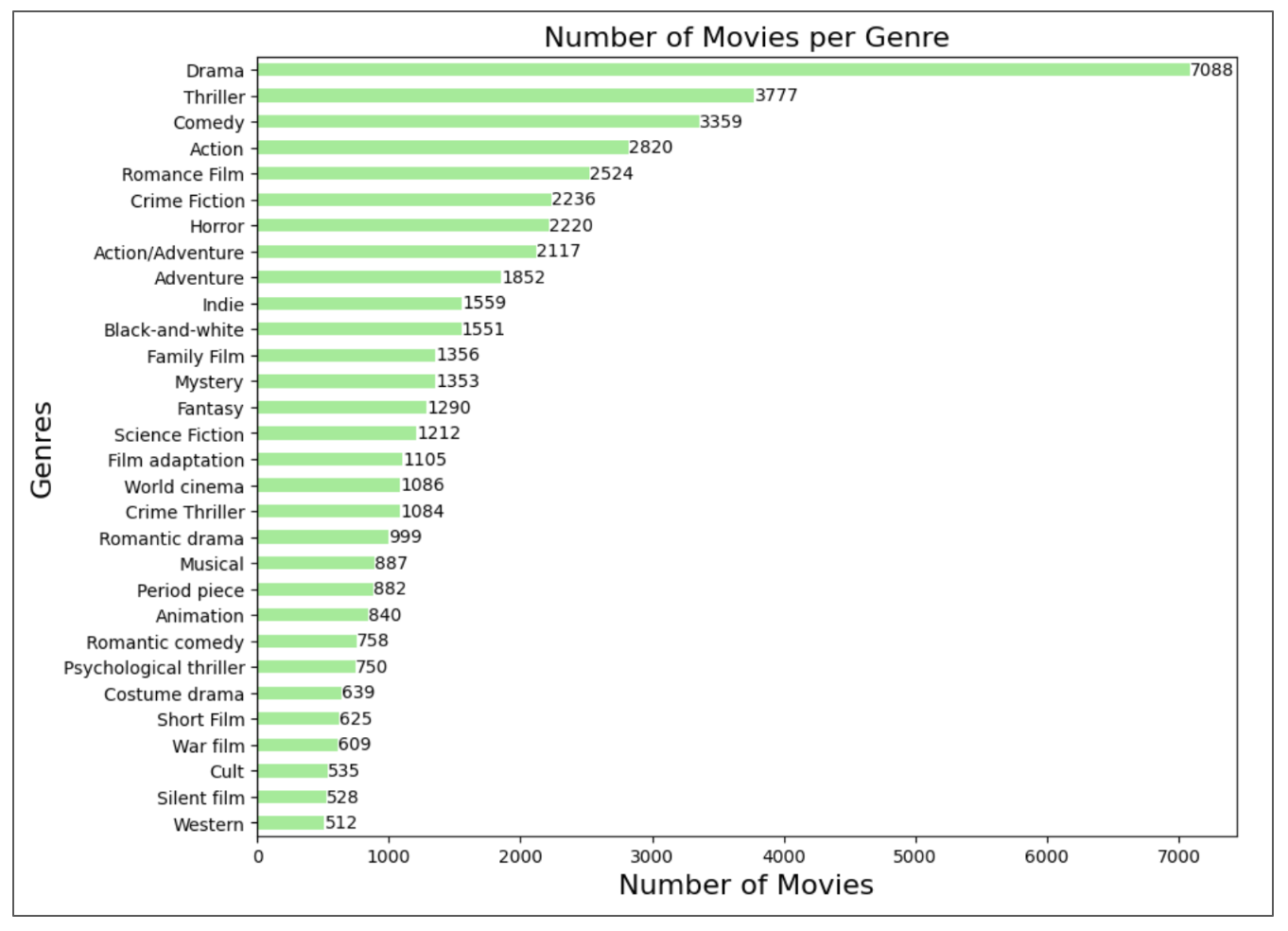
Drama takes the lead as the most popular genre by far (what can we say, people love a bit of drama!). Action, Romance, Crime and Horror also shine, showing that people enjoy laughter, love, excitement and also scaring themselves. On the other hand, niche genres like "Costume Drama" and "Western" are less common, loved by smaller, more specific audiences. It's important to note that a single movie can belong to multiple genres, which helps explain why Drama dominates. In fact, it often serves as a foundational element in many plots, adding emotional depth and sentimentality to keep audiences engaged. For instance, a Western movie might incorporate elements of action or crime, such as a murder mystery set in the desert.
Do words define genres?
Now, let’s have a quick look at what words appear often in the different genres:
(Note: it's possible that the plot is not shown on the website, if you see just a white empty square try to refresh ❄️ the page...)
From the word clouds across different genres, we observe that certain words, such as 'find,' 'tell,' 'one,' and 'see,' appear consistently
across all genres. This is expected, as these are commonly used words. However, their large presence makes it difficult to discern clear trends
or distinctions among the genres.
For specific genres such as Crime Thriller we can already guess the genres that it corresponds to by looking at the word
cloud only, with words such as 'kill', 'police', 'gun' or 'dead'.
But is genre alone enough to truly capture the essence of a movie? Not quite. The richness of a film lies in its story, the plot that unfolds and draws us in. By exploring the words used to describe films across genres, we can uncover patterns and themes that go beyond broad categories and discover new topics that might better describe the synopses.
Topics Detection
But how do we move from broad genres to the deeper, more intricate storytelling elements that truly define a movie? This is where topic modeling comes
into play. By analyzing the synopses that describe the essence of each film, we can uncover recurring themes and patterns that go beyond surface-level
genres.
To achieve this, we use Latent Dirichlet Allocation (LDA), an unsupervised machine learning method that takes as inputs a corpus of documents,
in our case the movie synopses, and a number of topics. It then groups documents into the given number of topics based on the semantics of the documents.
Each topic is defined as a distribution of words and each movie has a distribution across topics. This technique helps identify hidden topics within the movie synopses.
How many hidden topics are there within synopses?
However, as we saw in the word clouds above, to have consistent and more representative topics it’s better to remove stop words, character names or punctuation. Once this is done, we run the LDA algorithm on
synopses for a various number of topics. The goal is to find which number of topics fits our data best. For each LDA model, we use a coherence
score to measure how consistent the topics are.
Here is the graph of coherence as a function of the number of topics:
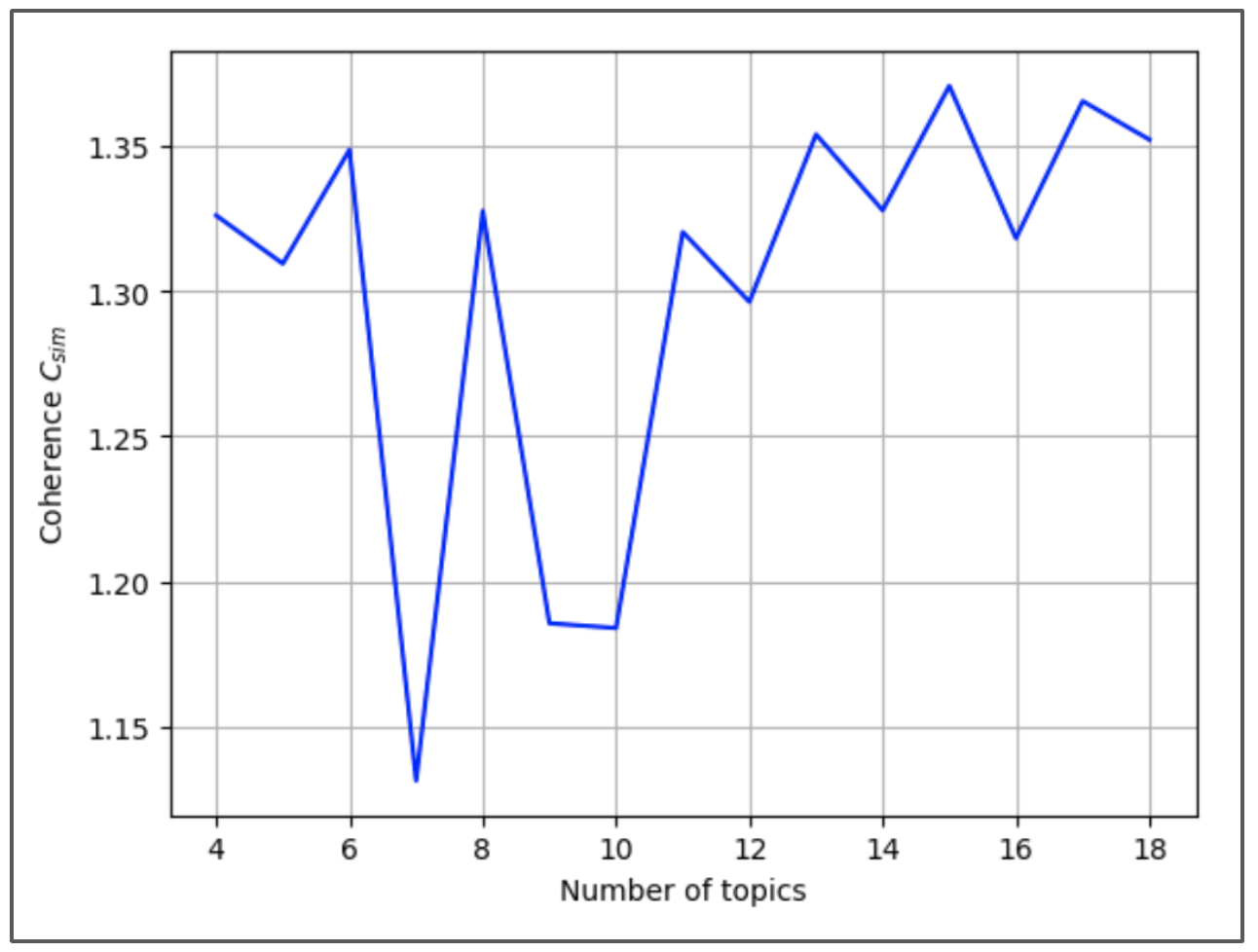
The most coherent number of topics is 15 since it gives the maximum coherence. This gives 15 different word distributions to which we attribute topic names using a Natural Language Processing model. Here are the 15 topics discovered by the LDA model:
| Topic | Keywords | Theme | Movie Example |
|---|---|---|---|
| 1 | police, car, murder | Crime and Pursuit | Flightplan |
| 2 | murder, woman, case | Investigative Drama | Great Expectations |
| 3 | say, ask, room | Domestic Suspense | Miracle |
| 4 | Beast, barricade, escape | Struggle and Sacrifice | Avenging Angel |
| 5 | game, team, treasure | Adventure and Teamwork | A Single Man |
| 6 | Macbeth, king, prophecy | Shakespearean Power Struggles | The Prisoner of Zenda |
| 7 | car, police, money | Urban Crime and Violence | Confessions of a Shopaholic |
| 8 | Sir, musketeer, airship | Historical and Heroic Tales | The Shop Around the Corner |
| 9 | Lincoln, look, life | Identity and Discovery | Kidnapped |
| 10 | say, money, love | Emotional Conflict and Drama | Frozen |
| 11 | house, vampire, family | Supernatural and Gothic | The Frozen Ground |
| 12 | love, family, school | Family and Everyday Life | The Forbidden Kingdom |
| 13 | guard, musketeer, sword | Adventure and Loyalty | Oliver Twist |
| 14 | say, look, castle | Drama and Character Interaction | Dungeons & Dragons: The Book of Vile Darkness |
| 15 | escape, attack, team | Action and Strategy | Scarface |
Woah interesting topics! Some of them resemble genres, for example Crime and Pursuit was expected and sounds similar to Crime and Thriller, but others are quite surprising. Identity and Discovery is a never-seen-before genre! Those topics feel like they reflect more the entire movie plot rather than overall ambiance. For example, the distinction between themes like Adventure and Teamwork versus Adventure and Loyalty brings insights into the core of the story.
Topics Exploration
With our 15 topics identified and labeled, we now turn our focus to understanding these topics in greater depth. The goal is to move beyond simply listing them and instead interpret
what each topic represents in the context of the movies it describes.
Let's explore the relationships between topics and their most relevant terms.
Side note: How to interact with the graph
- Selecting a topic (click on a circle, or select from the top bar): updates the right panel to show the most relevant terms for that specific topic.
- Hovering over a term (Right Panel): highlights its contribution to the topic (red bar) and its overall frequency (grey bar).
Now that you are a master at interacting with our plot, let’s analyze it. This plot has many information and it is normal to be confused, don't worry! Let's break it down together.
GRAPH ANALYSIS
The topics are ordered based on the percentage of tokens that were used to create them. By setting the relevance to 1 (λ=1) and then
hovering over the words of a certain topic we can see how much each topic uses this word. Words like "army" appear in most topics.
But in order to differentiate each other, the topics also have words specific to them that can be seen when setting the relevance to 0 (λ=0).
We can then see that for Topic 7, "MacBeth" is an important word specific to this topic.
While only topics 11 (Supernatural and Gothic), 10 (Emotional Conflict and Drama) and 7 (Urban Crime and Violence) are isolated from the rest, all other topics are still very different from each other. This is not evident
to see on the graph since the 15 dimensions of the topics are projected to only 2 dimensions.
Are topics linked to genres or labels?
While the graph analysis done previously highlights how topics are constructed and differentiated based on their keywords, it raises an important question: Do topics capture information or are
they just another way to encode genres or labels?
To investigate this, we explore the relationships between topics and features such as genres and MPST labels. By creating bipartite networks, we visualize how topics connect to genres and MPST labels. These networks help us uncover
overlaps and shared patterns, providing insights into how well the discovered topics correspond to existing categorizations.
Are topics subcategories of genres?
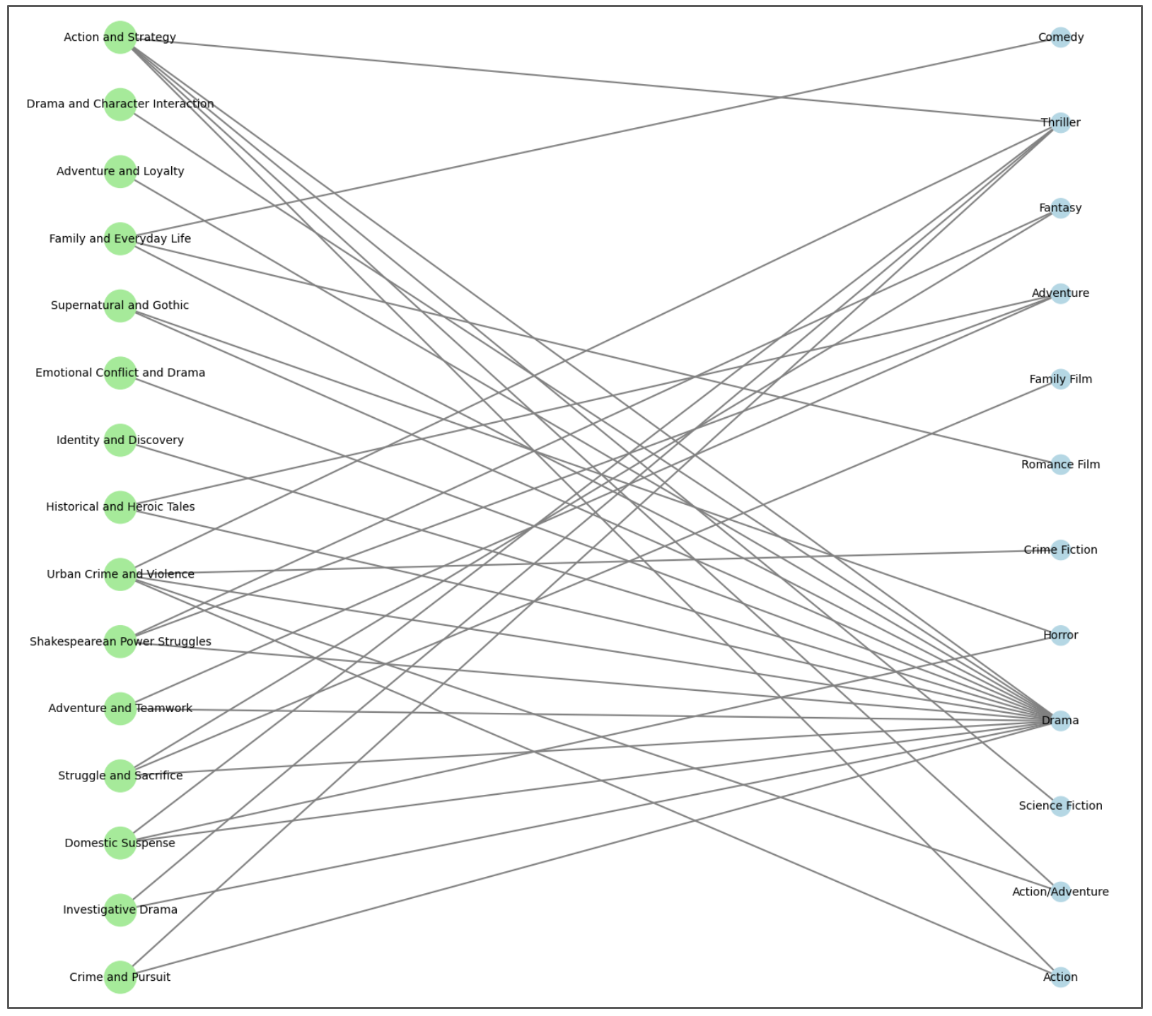
From the network analysis, we find that most genres and topics remain unlinked, as they lack sufficient associations. However, among the connected categories, Drama emerges as a dominant genre, appearing across multiple subtopics. This isn’t surprising, given Drama's popularity and its broad thematic reach. Interestingly, some topics act as genre hubs. For instance, Urban Crime and Violence tie together elements of Thriller, Drama, Adventure, and Crime Fiction illustrating how topics can aggregate multiple genres into cohesive narratives.
How are topics linked together based on genres similarity?
To understand the similarity between topics, we project the bipartite graph into a graph where only topics are nodes. In this projection, edges represent the number of genres shared by two topics.
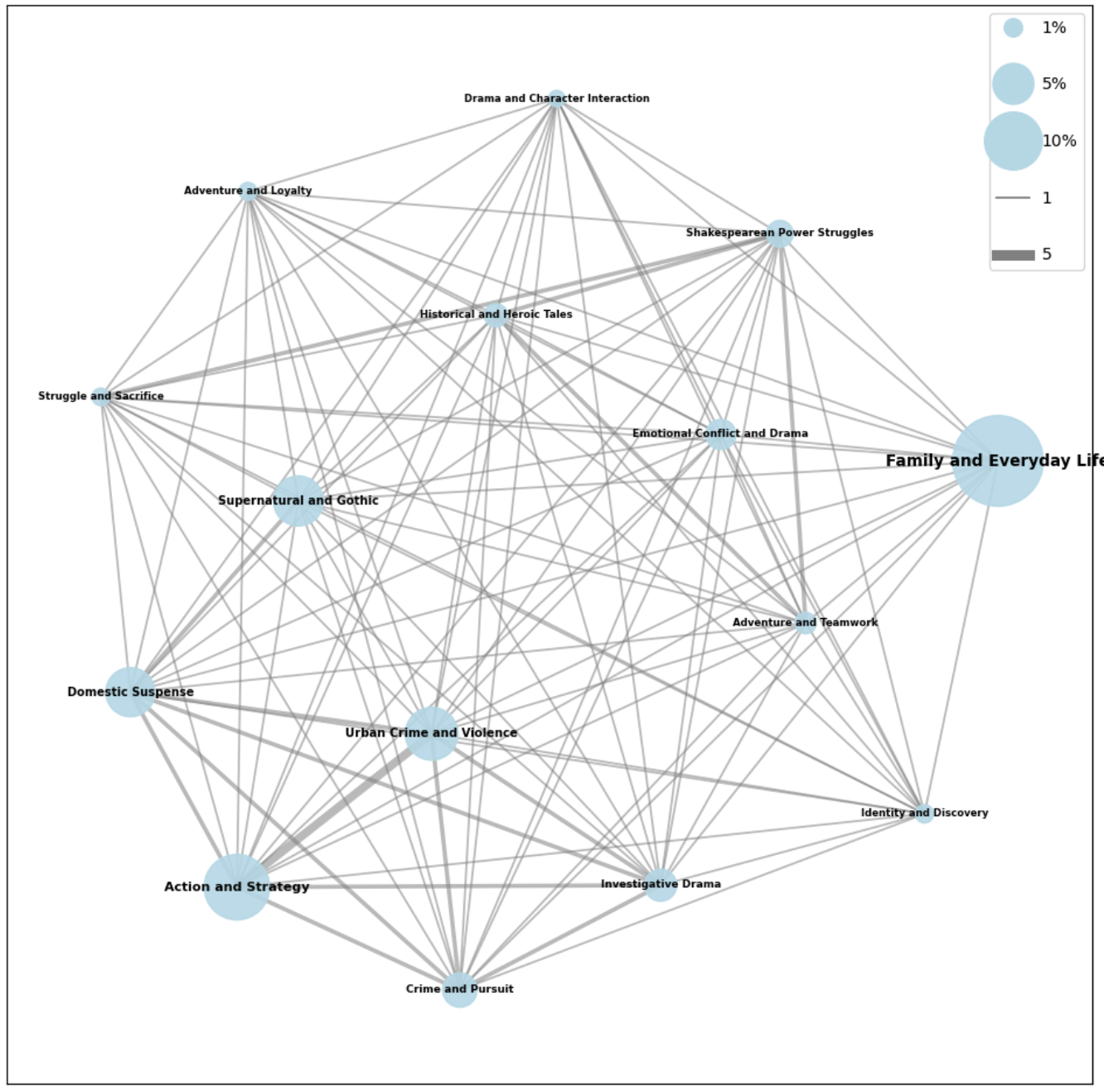
The overall connections between topics seem to make sense where topics that share similarities also appear close together on the graph. For instance, 'Shakespearean Power Struggles' is positioned near ‘Family and Everyday Life’, ‘Emotional Conflict and Drama’, ‘Historical and Heroic Tales’, and ‘Character Interaction and Drama’, which collectively define the essence of ‘Shakespearean power struggles’. The Family and Everyday Life topic emerges as the most prevalent main topic in our dataset, while Action and Strategy and Urban Crime and Violence share the highest number of genres.
So do topics reflect genres?
To assess if the topics are reflected by genres, we calculate the average probability of a random link between a topic and a genre. By comparing this random probability with the actual proportion of links in our graph, we can evaluate how well our topics are capturing the genres.
The independent probability of such a link is 0.004% , whereas the observed proportion of links in our graph is 1.289%. This significant difference indicates that our topics do reflect genre patterns to some extent!
Which Topics Are Associated with Specific Tags?
Let's do the same analysis with the labels of the MPST dataset added earlier instead of genres:
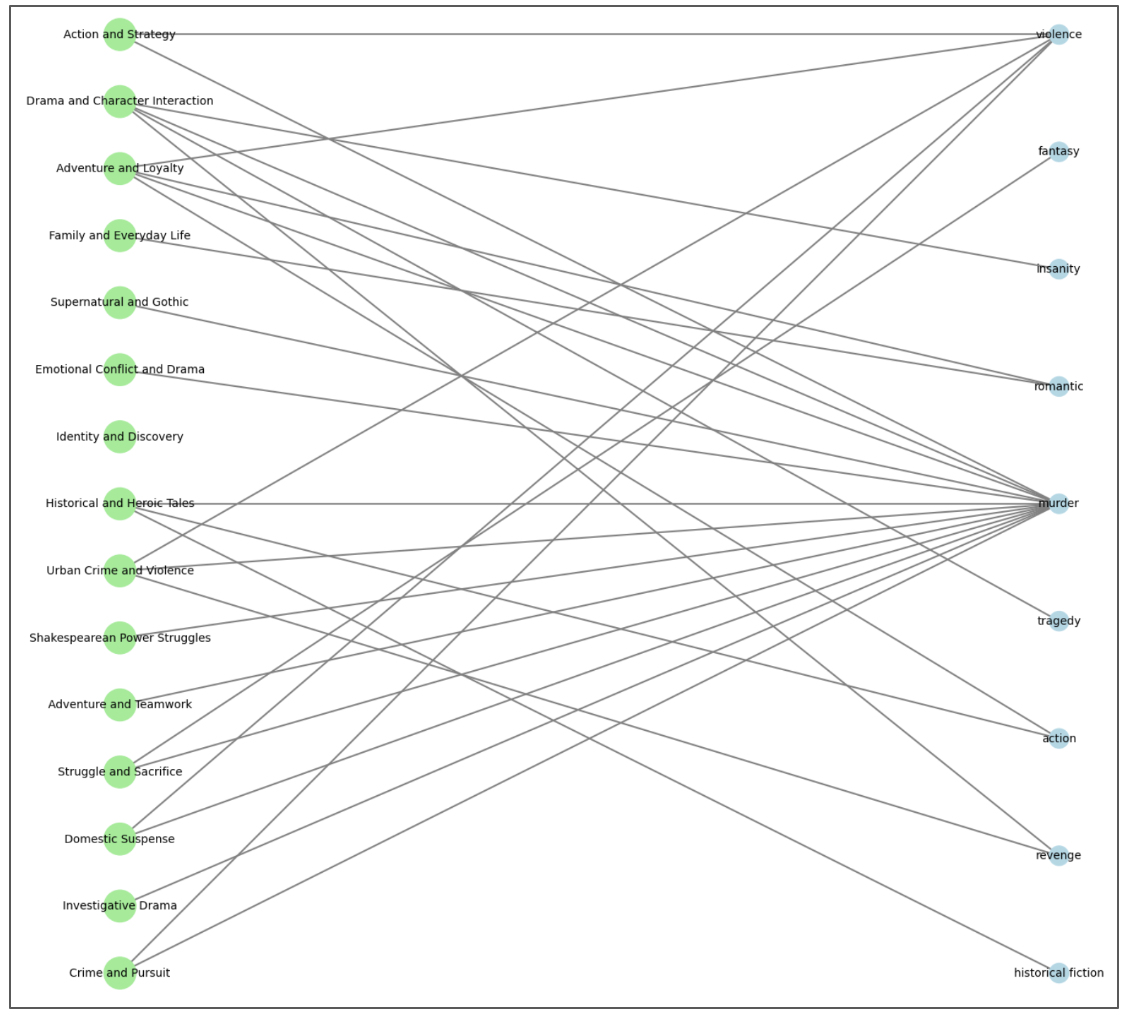
Most genres and topics remain disconnected, with only a few forming meaningful links. Among these, the Murder genre stands out, weaving through multiple subtopics. On the other hand, some topics act as major genres take Historical and Heroic Tales, which brings together subgenres like Historical Fiction, Action, and Murder into a cohesive narrative hub.
How are topics linked together based on tags similarity?
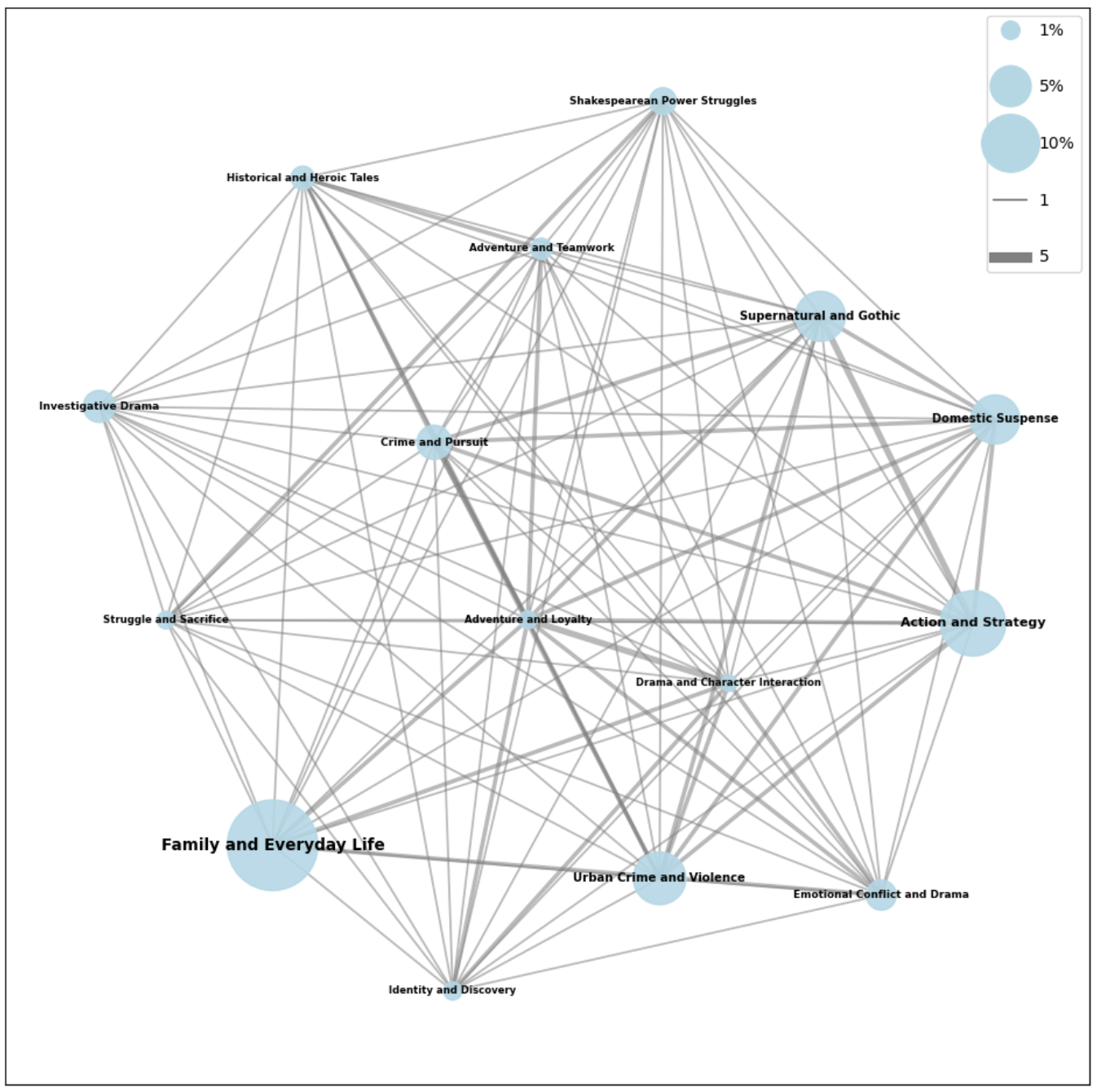
The links between topics seem to make sense where more similar topics share more links. Smaller topics, like Historical and Heroic Tales, Crime and Pursuit, and Adventure and Loyalty, tend to share the most tag connections.
So do topics reflect MPST labels?
The probability of link in a random relation between topics and labels would be 4.29% .
The proportion of link between topics and labels is also 4.29%.
The two percentages are identical, meaning that labels can be statistically random for our topics. We thus can not infer any trends between topics and tags from this network.
Movie Recommendations
Now that we’ve uncovered meaningful insights about movies through topic modeling and their connections to genres and labels, it’s time to put this knowledge to practical use. Imagine a scenario: you have a favorite movie, and you’re looking for something new to watch. Using the topics we’ve identified, we can recommend a movie based on their thematic similarity.
Here’s how it works: simply tell us a movie you like, and we’ll find the closest match by identifying a movie with the most similar topic distribution.
Ready to find your next favorite movie? Let’s get started!
(if you are not a big movie watcher you could try: Scarface, Dumbo, Oliver Twist or Fast and Furious)
Are topics enough for recommendations?
Since we can categorize movies by their topics, we have a sense of their plot similarity. But is plot similarity enough for a recommendation system?
To check this we begin by assuming that similar movies tend to have similar ratings. After all, recommending movies solely based on the highest ratings might not align with personal preferences, if someone enjoyed a cheesy, low-rated Christmas movie, they likely wouldn’t want to watch a critically acclaimed Cannes-winning film next.
Is this statement true across genres?
The boxplot shows the IMDb ratings distribution across the top 20 movie genres, and we can observe that all genres tend to follow a binomial distribution. Some have their means higher than others. For example "Fantasy" movies ratings have a mean around 7 while "Cult" movies have lower ratings with a mean around 6.
Each box represents the range of ratings for a specific genre, with the thick line in the middle indicating the median rating. Genres like Drama, Thriller, and Crime Thriller show a broad spread of ratings, with some movies rated both highly and poorly, leading to a greater variability. In contrast, Romantic Drama and Musical genres have slightly higher median ratings, reflecting a more consistent level of audience appreciation. On the flip side, Horror movies exhibit the widest variation, with a significant number of low-rated films pulling the overall average down.
Thus we will try to recreate this with our recommendations trying to recommend movies that exhibit similar ratings.
Is it already the case?
To explore this, we use PCA for dimensionality reduction, grouping similar topics together in the reduced space. Then, we examine whether movies with similar topics tend to have similar ratings by visualizing their rating distribution.
Here the 15 dimensions of the topics were reduced to 3 using PCA. This allows to visualize the clustering of movies based on their topics, where in fact more similar movies appear close together in this 3d space.
Do movies with similar plot share similar ratings?
Sadly, the ratings appear like salt pepper. In fact, it is verified that our similarity measure is not up to point with movie plot analysis only. Movies that are considered as very similar by LDA, appear to have very different ratings. Mhh… This means that we have not yet captured a good enough notion of similarity between movies. Maybe considering movies plot solely is not enough. What if features such as box-office, movie run time or the country in which it was produced could influence?
What features influence ratings the most?
Given our starting point that similar movies receive similar ratings, we need to understand which features are strong predictors of those ratings. This knowledge will help us uncover any features our current analysis might be overlooking. Does adding more features improve our movie rating prediction?
The findings are summarized in the table below:
| Feature | Top Positive Features | Top Negative Features |
|---|---|---|
| Tags | historical: 0.8600 atmospheric: 0.7694 realism: 0.7604 |
stupid: -0.6779 pornographic: -0.5650 comic: -0.1445 |
| Movie genres | period_horror: 3.5594 supermarionation: 2.1483 revisionist_fairy_tale: 1.9023 |
filipino_movies: -16.0249 z_movie: -6.1076 hardcore_pornography: -5.7777 |
| Movie languages | marathi_language: 1.3198 taiwanese: 1.2946 gujarati_language: 1.1842 |
bosnian_language: -2.5682 aboriginal_malay_languages: -1.8995 deutsch: -1.6033 |
| Movie countries | philippines: 15.4360 serbia_and_montenegro: 3.2067 bosnia_and_herzegovina: 2.5759 |
lithuania: -2.6671 aruba: -1.4518 bulgaria: -1.4302 |
| Numerical Importance | Movie runtime: 0.1358 numVotes: 0.1870 IMDB Box-office: 0.0033 |
Not applicable |
To do so, we trained a linear regression model containing both numerical and categorical features. For the categorical features, we used TF-IDF vectorization, a technique that transforms textual data into numerical representations, allowing the model to handle complex categorical information. Interestingly, our analysis revealed that categorical features play a much more significant role in predicting ratings compared to numerical ones.
Categorical features : Movie Genres and Tags play a significant role for ratings prediction. Additionally, Movie Countries and Movie Languages also appear relevant. Incorporating these features into our recommendation system could maybe enhance its effectiveness!
Numerical features: two standout features are the movie's runtime and the number of votes. Interestingly, box office earnings have minimal impact on ratings - just because a film makes money it doesn’t guarantee it will be well-received by the audience.
Conclusion
In conclusion, our journey into plot synopsis has revealed hidden thematic beyond familiar genres. With the help of LDA, we've moved beyond simple labels to illuminate nuanced topics within movie synopsis, uncovering meaningful connections and distinctions. While some topics naturally cluster around established genres, others encode new narrative spaces, offering fresh perspectives on how we categorize and understand films. Our initial approach to recommendations, driven by plot similarity, revealed that the story is just one piece of the puzzle. Recognizing this, we demonstrated the significant influence of factors like language and country of origin on movie ratings. Ultimately, the next step for a more sophisticated recommendation algorithm is one that not only understands the movie plot, but also where and how it has been made.
So, rest assured, the quest for your next favorite film just got a whole lot more interesting!